
About me
I am Hongjie Wang (王泓杰), a final-year Ph.D. candidate in the Department of Electrical and Computer Engineering at Princeton University, supervised by Prof. Niraj K. Jha. Before that, I received my B.S. degree with honor from Peking University (June 2021). You can find more information in my CV.
My research focuses on the efficiency of Machine Learning models, including but not limited to: (1) Vision Transformers, (2) Diffusion Models, (3) Vision-Language Models (Multimodal Generative Models), and (4) State Space Models. My research aims to make their training and inference more efficient and thus enable scaling them up for generation with higher quality. My recent projects focus on the hardware-agnostic efficiency enhancement of them, but I am also interested in the software-hardware co-design to boost their throughputs.
Please feel free to reach out via hongjiewang@princeton.edu if you share interests similar to mine! I am glad to chat and explore opportunities for collaboration.
Recent News
- 2025-06: Selected as the Outstanding Reviewer of CVPR 2025
- 2025-02: LinGen is accepted to CVPR 2025!
- 2025-01: Give a talk to Stability AI on LinGen
- 2024-12: Release our latest work LinGen, which provides linear-complexity for video generation
- 2024-05: Start my internship at Meta GenAI MovieGen Team
- 2024-02: Zero-TPrune and AT-EDM are accepted to CVPR 2024!
- 2024-01: Give a talk to Qualcomm on Zero-TPrune [slides]
- 2023-05: Start my internship at Adobe Research
Work Experience
- Meta GenAI MovieGen Team, Research Scientist Intern, May 2024 - Dec 2024
- Topic: Minute-Length Text-to-Video Generation with Linear Computational Complexity
- Mentor: Dr. Xiaoliang Dai
- Adobe Research, Research Scientist Intern, May 2023 - March 2024
- Topic: Efficient Text-to-Image Diffusion Models
- Mentor: Dr. Yuchen Liu
- Stanford University, Research Assistant, June 2020 - Sep 2020
- Topic: One-Shot Learning Accelerator
- Supervisor: Prof. Priyanka Raina
- Rice University, Research Assistant, June 2019 - Aug 2019
- Topic: Neural Network Training Accelerator
- Supervisor: Prof. Yingyan Lin (now at Georgia Tech)
Publications and Preprints
LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity
Hongjie Wang, Chih-Yao Ma, Yen-Cheng Liu, Ji Hou, Tao Xu, Jialiang Wang, Felix Juefei-Xu, Yaqiao Luo, Peizhao Zhang, Tingbo Hou, Peter Vajda, Niraj K. Jha, Xiaoliang Dai
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025 [paper] [project] [code]
Journal Extension (preprint) [paper]
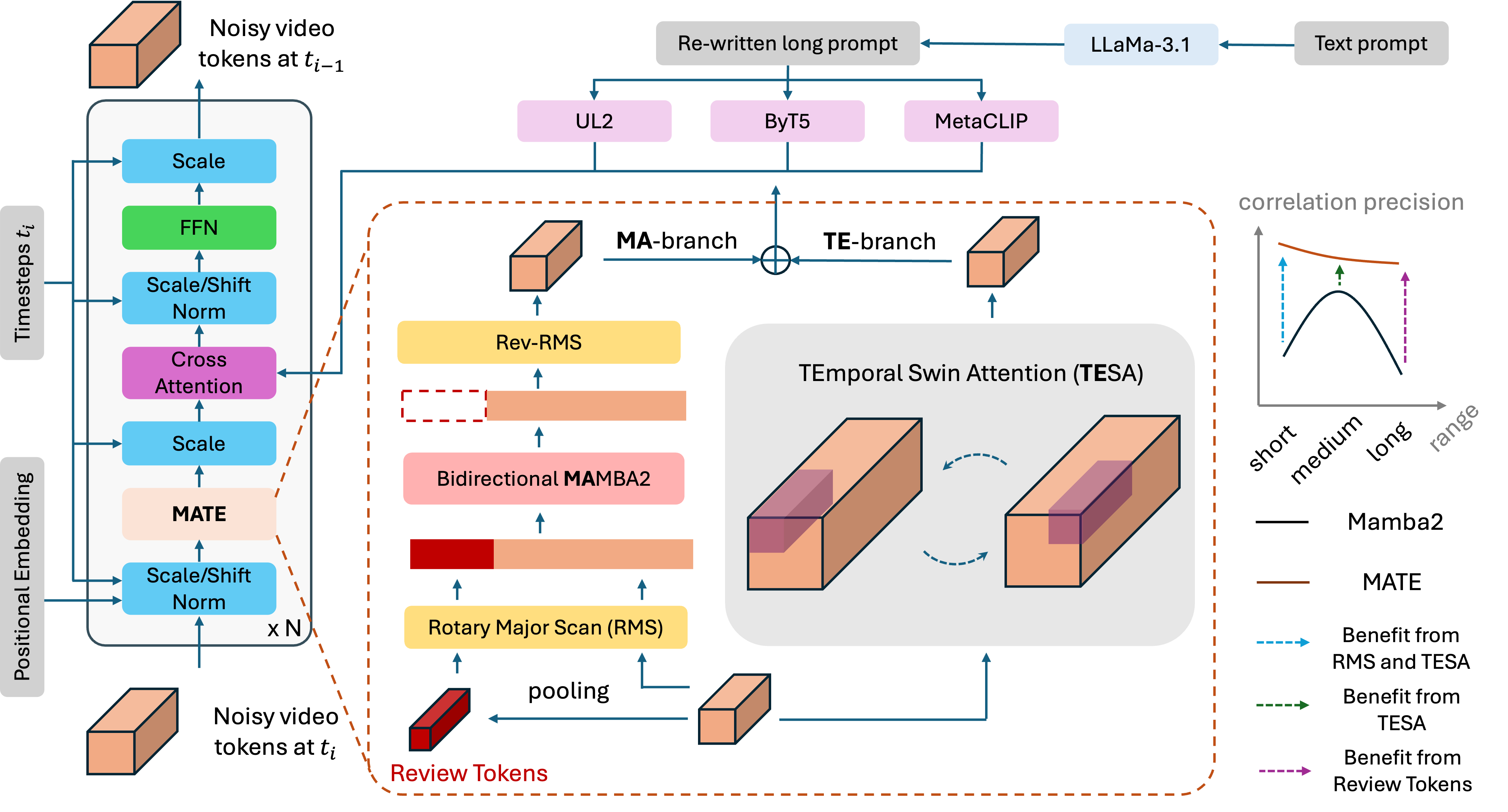
Highlight: For the first time, we demonstrate high-resolution 68-second video generation at 16fps on a single GPU — without relying on autoregressive extensions, super-resolution, or frame interpolation. Our approach achieves linear computational complexity, offering up to 15x speed-up over the standard DiT architecture, while delivering improved video quality and better text alignment. We believe this linear complexity provides extraordinary scalability, paving the way to hour-length movie generation.
AT-EDM: Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models
Hongjie Wang, Difan Liu, Yan Kang, Yijun Li, Zhe Lin, Niraj K. Jha, Yuchen Liu
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024 [paper] [project]
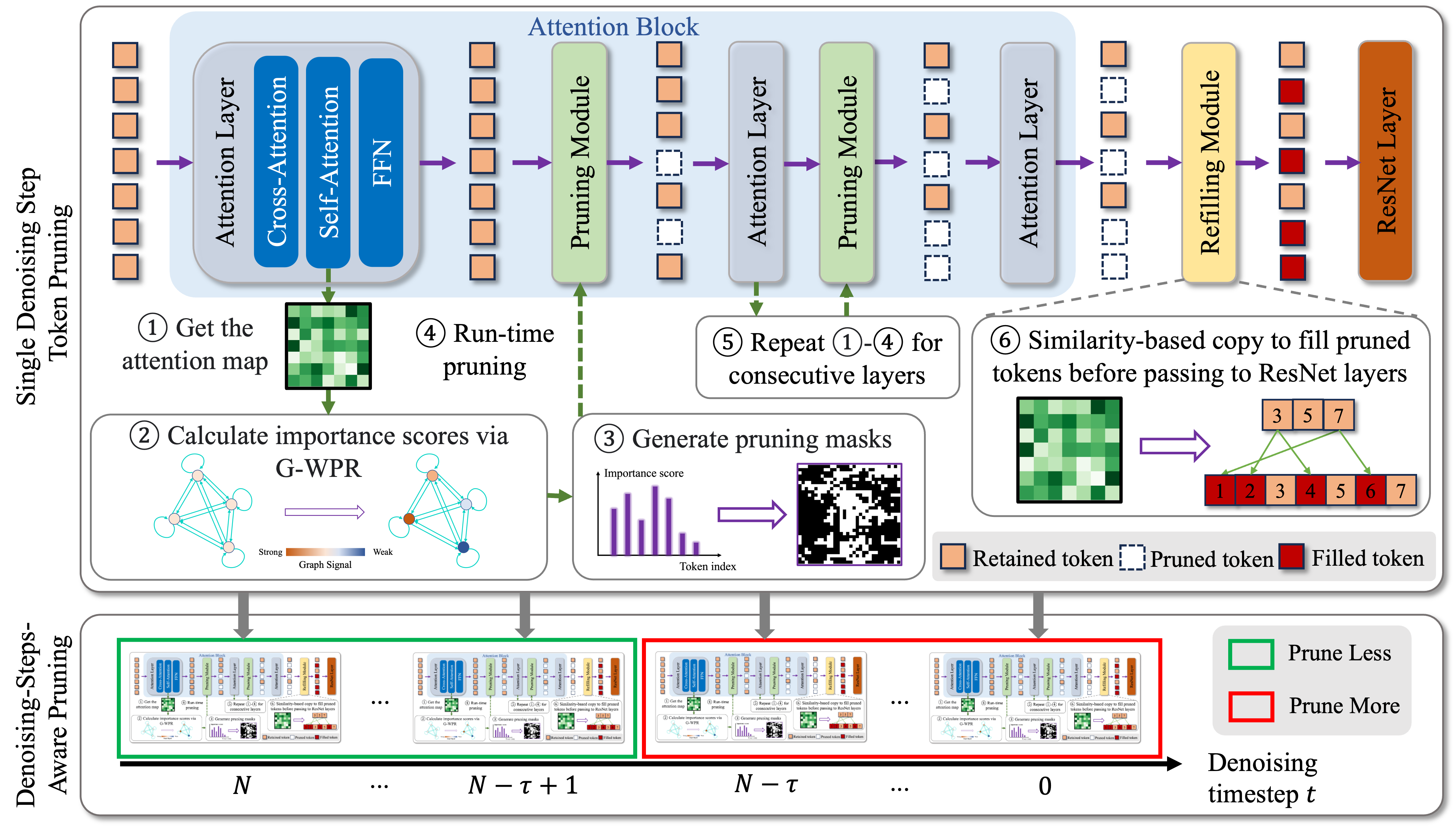
Highlight: We introduce the Attention-driven Training-free Efficient Diffusion Model (AT-EDM), a framework that leverages attention maps to perform run-time pruning of redundant tokens during inference without fine-tuning or performing GPU-intensive optimization on a certain loss function. AT-EDM reduces the FLOPs of the state-of-the-art open-source diffusion model, SD-XL, by 40% while keeping its FID and CLIP scores.
Zero-TPrune: Zero-Shot Token Pruning through Leveraging of the Attention Graph in Pre-Trained Transformers
Hongjie Wang, Bhishma Dedhia, Niraj K. Jha
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024 [paper] [project]
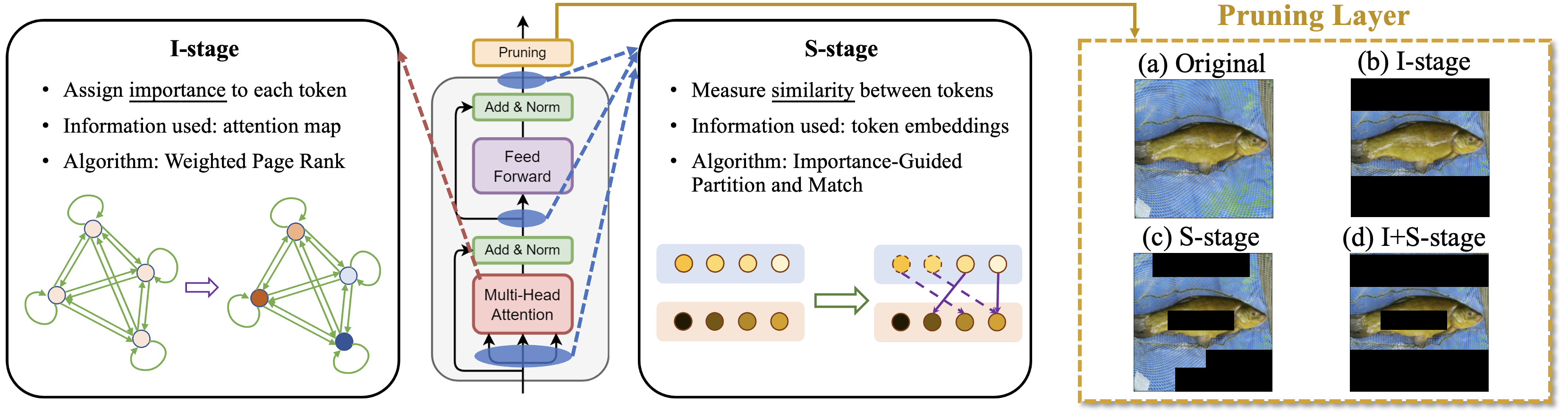
Highlight: We propose Zero-TPrune, the first zero-shot method that considers both the importance and similarity of tokens in performing token pruning. It leverages the attention graph of pre-trained Transformer models to produce an importance distribution for tokens via our proposed Weighted Page Rank (WPR) algorithm. It can be deployed on large Vision Transformers at negligible computational cost. Without any fine-tuning, Zero-TPrune reduces the FLOPs cost of DeiT-S by 34.7% and improves its throughput by 45.3% with only 0.4% accuracy loss.
Pre-PhD: Software-and-Hardware Co-Design for ML Acceleration
SAPIENS: A 64-kb RRAM-Based Non-Volatile Associative Memory for One-Shot Learning and Inference at the Edge
Haitong Li, Wei-Chen Chen, Akash Levy, Ching-Hua Wang, Hongjie Wang, Po-Han Chen, Weier Wan, Win-San Khwa, Harry Chuang, Y.-D. Chih, Meng-Fan Chang, H.-S. Philip Wong, Priyanka Raina.
IEEE Transactions on Electron Devices (2021) [paper]
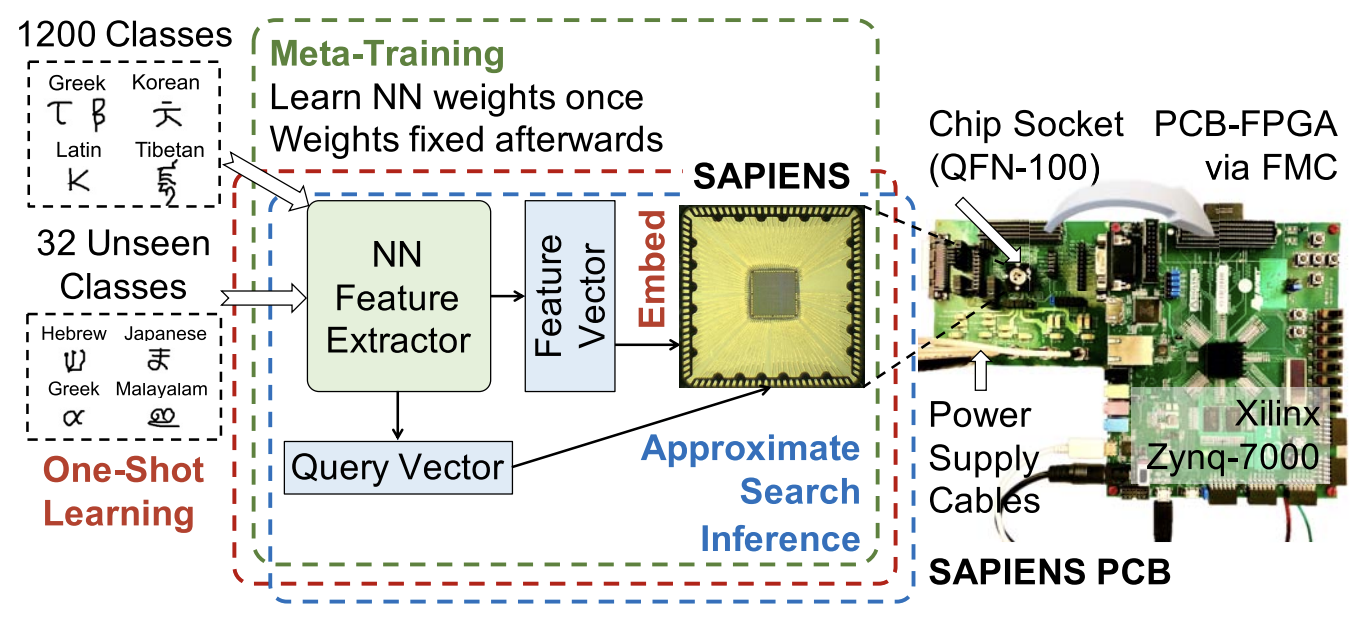
Highlight: We present the first chip-level demonstration of one-shot learning with Stanford Associative memory for Programmable, Integrated Edge iNtelligence via life-long learning and Search (SAPIENS), a resistive random access memory (RRAM)-based non-volatile associative memory (AM) chip that serves as the backend for memory-augmented neural networks (MANNs).
One-Shot Learning with Memory-Augmented Neural Networks Using a 64-kbit, 118 GOPS/W RRAM-Based Non-Volatile Associative Memory
Haitong Li, Wei-Chen Chen, Akash Levy, Ching-Hua Wang, Hongjie Wang, Po-Han Chen, Weier Wan, H.-S. Philip Wong, Priyanka Raina
IEEE Symposia on VLSI Technology and Circuits (VLSI) 2021 [paper]
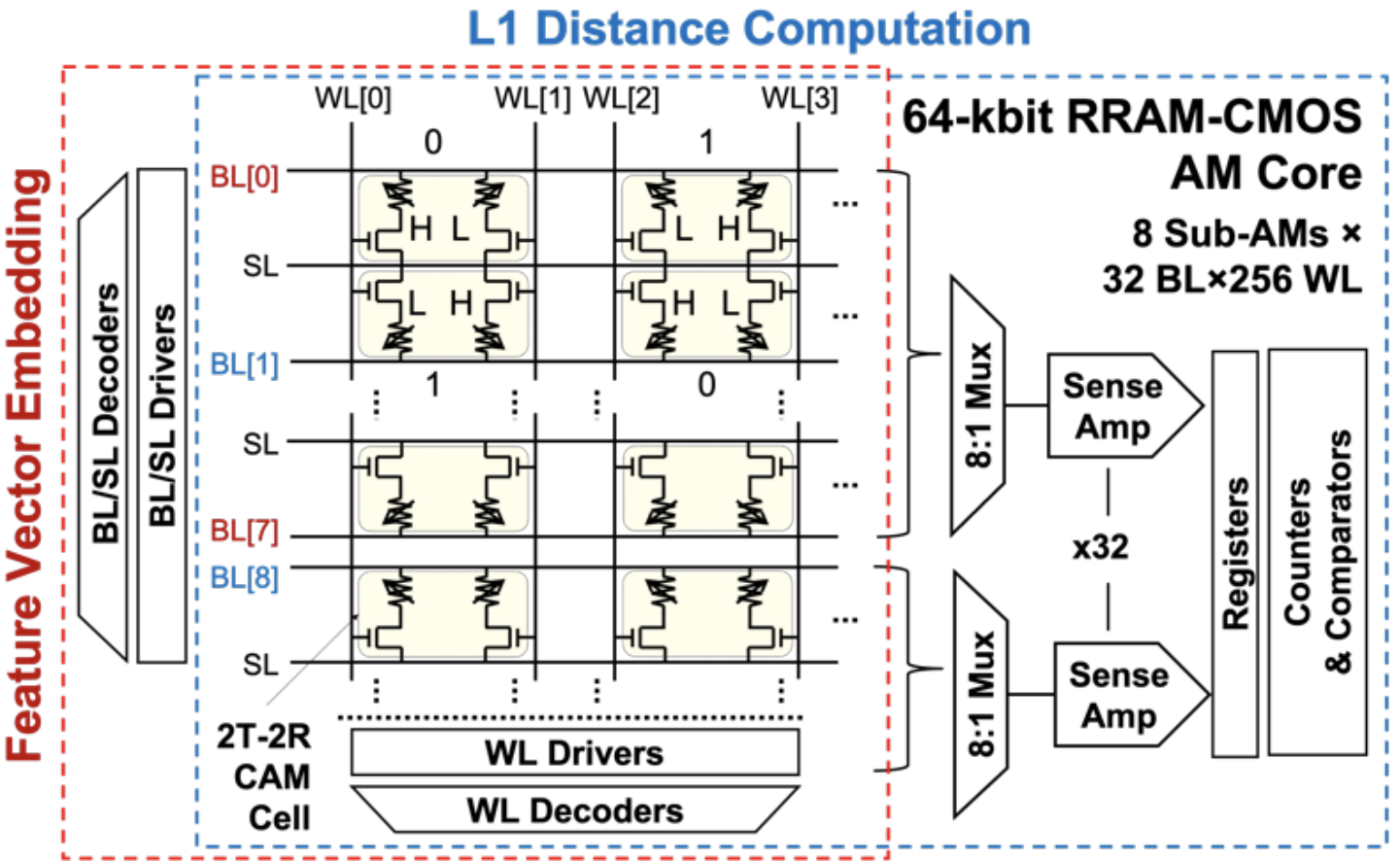
Highlight: Using only one example per class for 32 unseen classes during on-chip learning, our AM chip achieves ~72% measured inference accuracy on Omniglot as the first chip accuracy report compared to software accuracy (~82%), while reaching 118 GOPS/W for in-memory L1 distance computation and prediction.
A New MRAM-based Process In-Memory Accelerator for Efficient Neural Network Training with Floating Point Precision
Hongjie Wang, Yang Zhao, Chaojian Li, Yue Wang, Yingyan Lin
IEEE International Symposium on Circuits and Systems (ISCAS) 2020 (Oral) [paper]
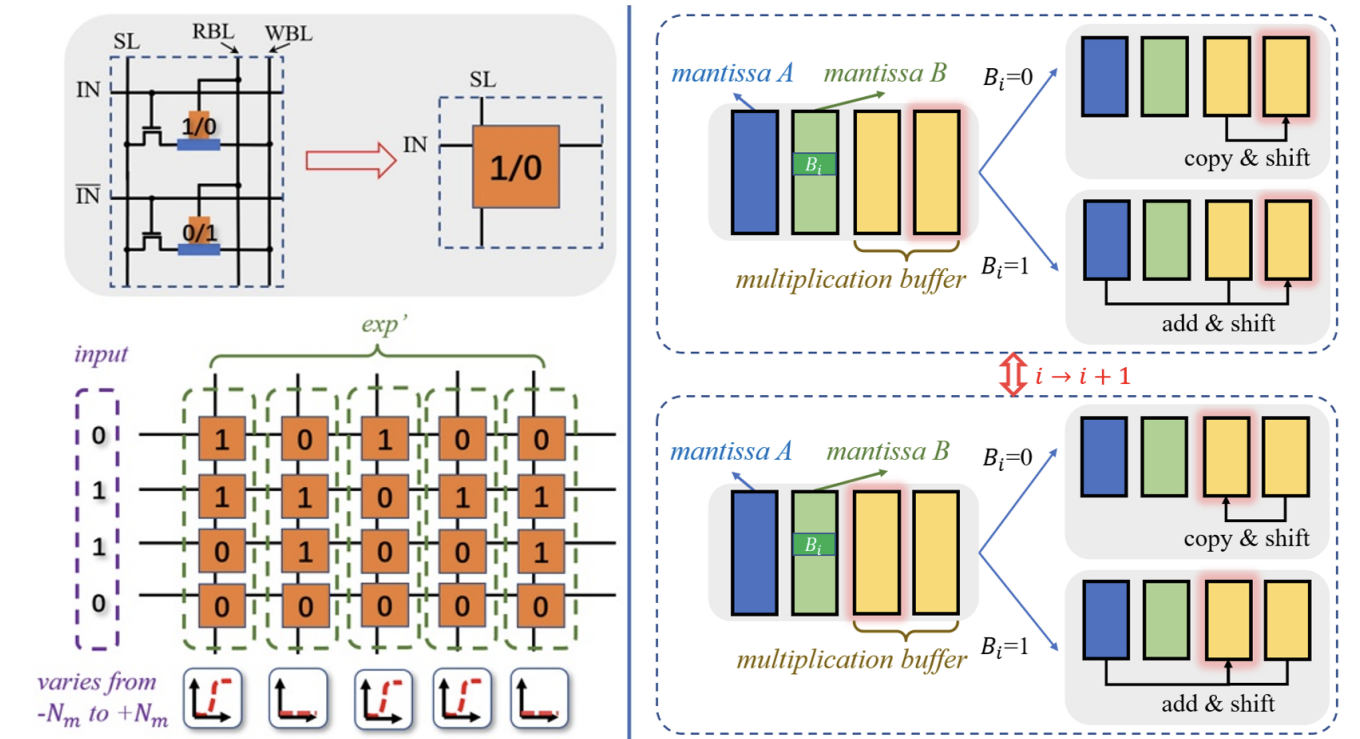
Highlight: We propose a SOT-MRAM based digital Process In-Memory accelerator that supports floating point precision. It can achieve 3.3×, 1.8×, and 2.5× improvement in terms of energy, latency, and area, respectively, compared with a state-of-the-art PIM based DNN training accelerator.
Academic Service
- Served (or serving) as a reviewer for
- CVPR 2024, 2025, 2026
- SIGGRAPH Asia 2025
- ECCV 2024, 2026
- ICCV 2025
- BMVC 2026
- WACV 2026
- NeurIPS 2024, 2025
- AISTATS 2025, 2026
- COCOON 2025
- IEEE Transactions on Image Processing (TIP)
- International Journal of Computer Vision (IJCV)
- IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
- IEEE Internet of Things Journal (IoT-J)
- IEEE ISCAS 2021
Selected Awards
- Outstanding Reviewer of CVPR 2025, IEEE/CVF, 2025
- Fellowship in Natural Science and Engineering, Princeton University, 2021
- Excellent Graduate, Peking University, 2021
- Xiaomi Scholarship, Peking University, 2020
- National Scholarship, Peking University, 2019
- May 4th Scholarship, Peking University, 2018
- Student of Merits, Peking University, 2017-2021
- Gold Medal in 33rd Chinese Physics Olympiad, 2016